Monte Carlo Method: Quasi vs. Pseudo-random
Although neural networks is taking the stage of AI these days, other approaches such as monte carlo methods are still relevant. In some cases, such as Alphago Zero, where a playing agent learns without any prior knowledge, neural network approaches are complemented with monte carlo simulation.
When is random random enough?
Usually in day to day code, there is a random() function that gives us a single dimenstion random quantity. In some places, to achieve entropy even lava lamps and webcams are used. These are called pseudo random numbers, are useful when a single sample is needed, in applications such as cryptography and gambling apps. However, the pseudo random numbers have are not distributed in even way. This causes a kurtosis fenomenum which impairs the performance of random-based simulations such as this exemple. A good example is the classic experiment of findig π by random point generation over a circle. The ratio between points inside and outside will approximate Pi by a fraction. This approach is described here and here
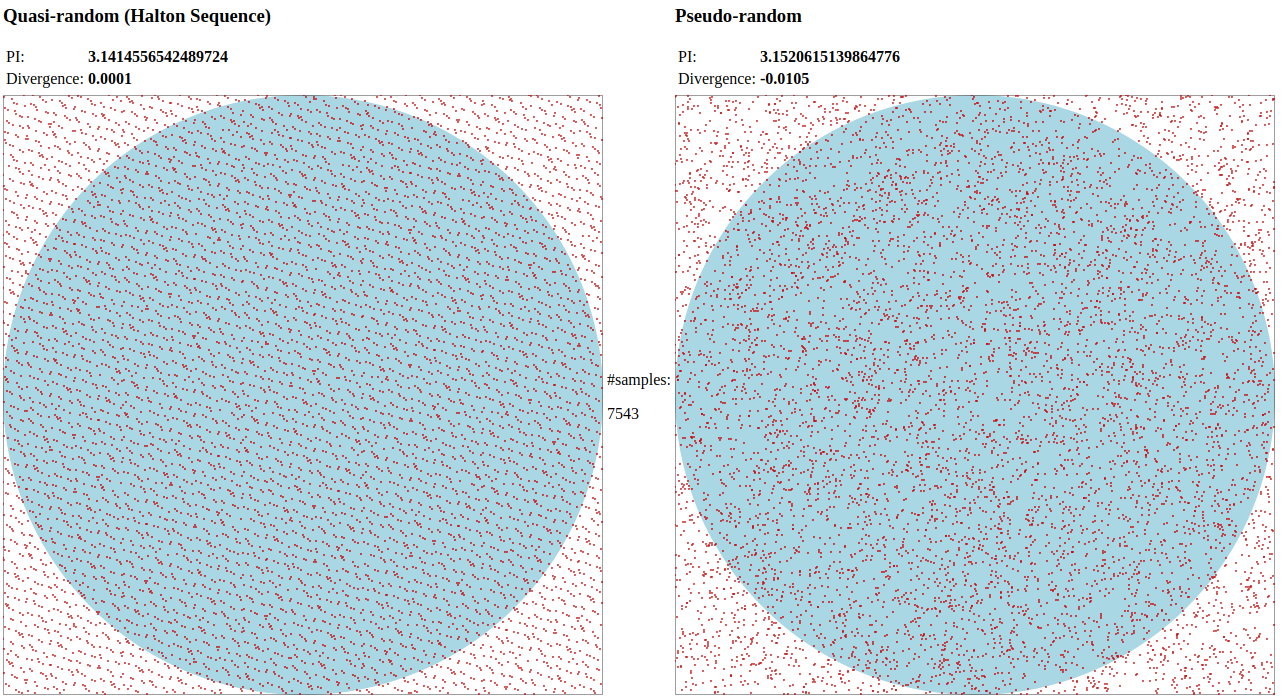
As ilustrated above, after 7000 samples, the quasi-random generator is converging faster than the pseudo random.
####Code
Done in web assembly, experiment was done in C, compiled to WebAssembly. The following snippet illustrates the generation of quasi-random sequence. For the pseudo random, the system library was used.
#define PRIME_X 5
#define PRIME_Y 17
float van_der_corput_number(int n, int prime_base) {
float ret = 0.0;
float denom = 1.0;
while(n > 0) {
denom = denom * prime_base;
float rem = n % prime_base;
n = n / prime
ret = ret + (rem / denom);
}
return ret;
}
Point quasi_random_point(int max, int seq) {
Point ret;
ret.x = (double)van_der_corput_number(seq, PRIME_X) * (double)max;
ret.y = (double)van_der_corput_number(seq, PRIME_Y) * (double)max;
return ret;
}
All code is in Github, and also a demo.","Although neural networks is taking the stage of AI these days, other approaches such as monte carlo methods are still relevant. In some cases, such as Alphago Zero, where a playing agent learns without any prior knowledge, neural network approaches are complemented with monte carlo simulation.